资讯
体育游戏app平台CPU 目下有 12 个中枢-kaiyun欧洲杯app(官方)官方网站·IOS/安卓通用版/手机APP下载
发布日期:2024-08-02 05:47 点击次数:88
AMD 新款 4 纳米\"Strix Point\"迁移处置器的首张芯片像片浮出水面,这要归功于中国应答媒体上的一位发热友。\"Strix Point\"的芯片尺寸较着大于\"Phoenix\"。它的尺寸为 12.06 毫米 x 18.71 毫米(长 x 宽),而\"Phoenix\"的尺寸为 9.06 毫米 x 15.01 毫米。芯片尺寸的加多主要来自于更大的 CPU、iGPU 和 NPU。工艺从\"Phoenix\"过火养殖产物\"Hawk Point\"的台积电 N4 改换为较新的台积电 N4P 节点。
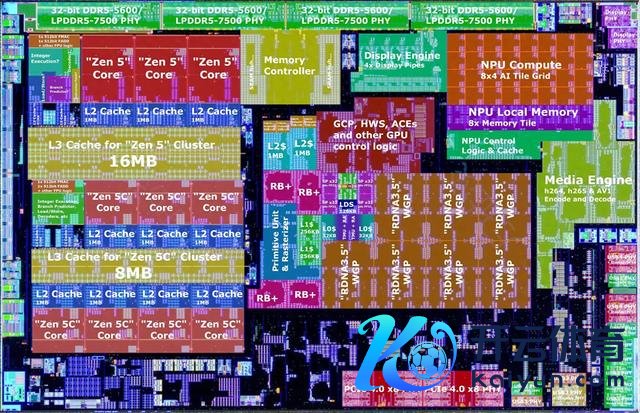

Nemez (GPUsAreMagic)防卫注目了裸片截图。CPU 目下有 12 个中枢,散播在两个 CCX 上,其中一个包含 4 个\"Zen 5\"中枢,分享 16 MB 三级缓存;另一个包含 8 个\"Zen 5c\"中枢,分享 8 MB 三级缓存。这两个 CCX 通过 Infinity Fabric 与芯片的其他部分说合。畸形大的 iGPU 位于芯片的中央区域。它基于 RDNA 3.5 图形架构,领有 8 个责任组处置器 (WGP),或 16 个缠绵单位 (CU),价值 1,024 个流处置器。其他关键组件包括 4 个渲染后端(16 个 ROP)和死心逻辑。GPU 有我方的 2 MB 二级缓存,用于缓冲向 Infinity Fabric 的传输。
与 iGPU 略有不同的是其关连组件--媒体引擎和泄露引擎。媒体引擎为 h.264、h.265 和 AV1 以及几种传统视频程序的编码息争码提供硬件加快。泄露引擎空隙将 iGPU 的帧输出编码为多样贯串器程序(如 DisplayPort、eDP、HDMI),包括硬件加快泄露流压缩;而泄露物理层器件则处置贯串器的物理层。
NPU 是\"Strix Point\"的第三个主要逻辑组件。AMD 的第二代 NPU 较着大于\"Phoenix\"中的 NPU。它基于更先进的 XDNA 2 架构,包含 32 个东说念主工智能引擎瓦片,可与我方的高速腹地内存和与 Infinity Fabric 接口的死心逻辑对话。该 NPU 的想象舒适并特出了 Microsoft Copilot+ 的硬件条款,可提供 50 TOPS 的浑沌量。
内存死心器赞助双通说念(160 位)DDR5(本机 DDR5-5600)和 128 位 LPDDR5(速率高达 LPDDR5-7500)。Nemez 指出,\"Phoenix 2\"和\"Phoenix\"芯片上也有这种 SRAM 缓存,但\"Raphael\"和\"Dragon Range\"中的 cIOD 内存死心器上莫得。
\"Strix Point\"芯片的 PCIe 根复合体比\"Phoenix\"小,而\"Phoenix\"的根复合体又比\"Cezanne\"小。在已往的三代产物中,AMD 一直在将 PCIe 通说念数减少 4 个。\"Cezanne\"具有 24 条 PCIe Gen 3 通说念(x16 PEG + x4 NVMe + x4 芯片组总线或 GPP);而\"Phoenix\"则将其裁汰为 20 条 PCIe Gen 4 通说念(x8 PEG + x4 NVMe + x4 芯片组总线或 GPP + x4 建树为 USB4)。较新的\"Strix Point\"则将其进一步缩减至 16 条 PCIe Gen 4 通说念(x8 PEG + x4 NVMe + x4 建树为 USB4 或 GPP)。
减少 PCIe 通说念背后的理念是,\"Strix Point\"旨在与\"Lunar Lake\"对决,后者也惟一 x4 的 PEG/GPP 通说念,而当\"Arrow Lake-H\"和\"Arrow Lake-HX\"最终面世时,它们将遭逢 AMD 的\"Fire Range\"芯片,后者领有 28 条 PCIe Gen 5 接口,致使不错与最快的孤苦迁移 GPU 配对。